
Large Millimetric Telescope, Puebla Mexico
Temas de Interés para tesis de Maestría y/o Doctorado

Los temas están listados en dos categorías separadas, la primera corresponde a métodos generales de agrupamiento (clustering), aprendizaje,
reconocimiento de patrones o clasificación. Desarrollo de modelos y algoritmos con capacidades de razonamiento, aprendizaje, toma
de decisiones y optimización que generen el comportamiento y desempeño adecuado para solucionar problemas de áreas de investigación
como las que se listan en la segunda parte, principalmente en áreas como; Interfaces Cerebro Computadora (BCI),
Procesamiento de Habla y Llanto de Bebe, y Procesamiento y Clasificación de Bioseñales en general.
MÉTODOS GENERALES:
- Máquinas de aprendizaje extremo basado en campos receptivos locales
- Maquina de Aprendizaje Extremo Tanimoto Ponderada (T-Welm)
- Proyección semi-aleatoria de reducción de dimensionalidad y Maquinas de Aprendizaje Extremo en el espacio de alta dimensión
- Aprendizaje por Refuerzo Difuso
- Sistemas de Inferencia Difusos optimizados con Enjambres de Particulas basados en Grupos Evolutivos
- Granularidad de información en modelos GrC Fuzzy
- Inducción descendente de árboles de patrones difusos
- Modelado Difuso granular con Hipercajas Evolutivas en Espacio Multidimensional de Señales de EEG
- Modelos Difusos Granulares
APLICACIONES DE INTERÉS
- Procesamiento de Bio Señales
- Resultados del método de formación de redes neuronales de Levenberg-Marquardt en aplicaciones nariz electrónica
MÉTODOS GENERALES
Máquinas de aprendizaje extremo basado en campos receptivos locales (Local Receptive Fields Based Extreme Learning Machine)
Las Máquinas de Aprendizaje Extremo (ELM), que fueron propuestas originalmente para redes neurales "generalizadas" con una sola capa oculta (SLFNs), ofrecen soluciones de aprendizaje unificado y eficaz para las aplicaciones de aprendizaje de características, agrupamiento, regresión y clasificación. Las teorías ELM muestran que las neuronas ocultas son importantes, pero no tienen por qué ser entrenadas de forma iterativa. De hecho, todos los parámetros de nodos ocultos pueden ser independientes de las muestras de entrenamiento y generadas de forma aleatoria de acuerdo con cualquier distribución de probabilidad continua. Y las redes ELM obtenidas satisfacen la aproximación universal y la capacidad de clasificación.
La arquitectura general de ELM conectadas localmente, muestran que: 1) las teorías ELM son naturalmente válidas para conexiones locales, introduciendo de este modo los campos receptivos locales a la capa de entrada; 2) cada nodo oculto en ELM puede ser una combinación de varios nodos ocultos (una subred), que también es consistente con las teorías ELM.
En general, la arquitectura básica ELM consta de d neuronas de entrada conectadas con cada dimensión del espacio de entrada, que están completamente conectadas con h neuronas ocultas por el conjunto de pesos wj (seleccionados al azar de alguna distribución arbitraria) y un conjunto de umbrales bj (también seleccionados al azar). Dada una función de activación no lineal generalizada, G se puede expresar la activación de las neuronas ocultas matriz H para todo el conjunto de entrenamiento
Maquina de Aprendizaje Extremo Tanimoto Ponderada (T-Welm)
A diferencia de la ELM clásica, el enfoque Tanimoto selecciona neuronas ocultas al azar de un conjunto de entrenamiento en lugar de algúna distribución continua arbitraria. De esta manera, asegurando, por una parte, que los pesos utilizados son binarios y escaso y, por otro, que abarcan correctamente el espacio de muestra (posiblemente muy degenerado). Esto es conceptualmente similar a tomar funciones ortogonales lo que asegura abarcar mejor todo el Rd, pero se enfoca en un subconjunto muy pequeño del espacio de entrada, que en realidad está lleno de puntos de datos.
Proyección semi-aleatoria de reducción de dimensionalidad y Maquinas de Aprendizaje Extremo en el espacio de alta dimensión
Proyección aleatoria (RP) es una técnica popular para la reducción de dimensionalidad debido a su alta eficiencia computacional. Sin embargo, RP no puede producir espacio de bajas dimensiones altamente discriminativo para producir el mejor rendimiento en clasificación de patrones porque la matriz de transformación aleatoria de RP es independiente de los datos. T resuelve este problema en un marco de proyección semi-aleatoria (SRP), que tiene el mérito de muestreo de características aleatorias de RP, pero emplea mecanismo de aprendizaje en la determinación de la matriz de transformación.
Una ventaja de SRP es que se logra un buen equilibrio entre complejidad computacional y la precisión de clasificación. Otra ventaja de SRP es que múltiples módulos de SRP se pueden apilar para formar una arquitectura de aprendizaje profundo para un aprendizaje de característica compacto y robusto. Además, con base en el conocimiento de la relación entre RP y Extreme Machine Learning (ELM), la SRP se aplica a ELM para derivar una ELM parcialmente conectada (PC-ELM). Los nodos ocultos de la PC-ELM son más discriminativos y por lo tanto se necesita un menor número de nodos.
Aprendizaje por Refuerzo Difuso
Los sistemas de inferencia difusos incorporan el conocimiento humano en su base de conocimientos en las conclusiones de las reglas difusas, que se ven afectadas por decisiones subjetivas. En Aprendizaje por Refuerzo Fuzzy las técnicas de aprendizaje por refuerzo se pueden utilizar para afinar la parte de conclusión de un sistema de inferencia borrosa. Entre las técnicas que se probarán son: TD (diferencia temporal) y GA (algoritmo genético) basado en refuerzo.
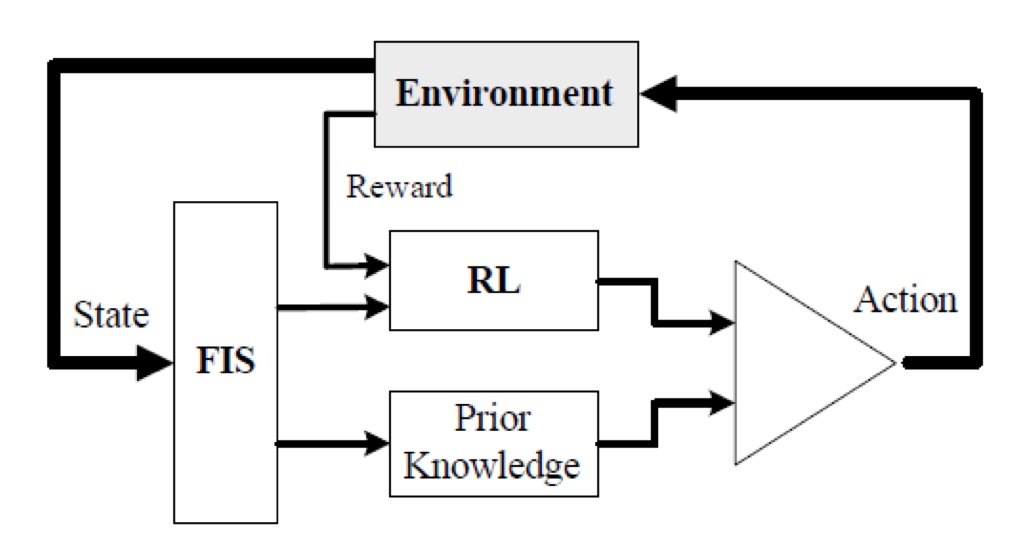
Sistemas de Inferencia Difusos optimizados con Enjambres de Particulas basados en Grupos Evolutivos (Evolutionary-Group-Based Particle-Swarm-Optimized Fuzzy Inference Systems)
La Optimizacion por Enjambres de Particulas basados en Grupos Evolutivos (EGPSO) utiliza un marco para incorporar nuevas operaciones de cruza y mutación en PSO. De acuerdo con los grupos formados de manera adaptativa en un enjambre, se utiliza una operación de cruce basada en grupos (GCRO). Una operación de velocidad mutada adaptativa (AVMO) puede ser incluida para mutar la velocidad de cada partícula. EGPSO se ha usado para problemas de diseño de sistemas de inferencia difusos (FIS). En particular, se han aplicado a la navegación evolutiva de robots móviles, en búsqueda de objetivo libre de colisiones (TS), en entornos desconocidos.
Granularidad de información en modelos GrC Fuzzy.
De acuerdo a la Computación Granular (Gr), la información de granularidad de una estructura granular es una medida de la incertidumbre acerca de su estructura actual. En general, la granularidad de información representa la capacidad de discernibilidad de información en una estructura granular. Cuanto menor es la granularidad de información, más fuerte es su capacidad de discernibilidad. Cómo calcular la granularidad de información de una estructura granular sigue siendo un tema abierto.
El concepto de medida de granulación se utiliza para medir la incertidumbre de la información en bases de conocimientos. La granularidad de la información ha sido aplicada de manera efectiva en la medición de significancia de atributos, la selección de caracteristicas, extracción regla, etc., en cualquier conjunto de datos completos o incompletos. Un método usado se basa en una combinación de granulación con el contenido de conocimientos de naturaleza intuitiva para medir el tamaño de granulación de la información en una base de conocimientos. La medición de la rugosidad de un conjunto aproximado también ha sido utilizada, tomando, en un sentido amplio, la rugosidad como un tipo de granularidad de información.
Inducción descendente de árboles de patrones difusos (Top-Down Induction of Fuzzy Pattern Trees)
La Inducción de árboles de patrones difusos es un método novedoso de aprendizaje automático para clasificación. En términos generales, un árbol de patrones es una estructura jerárquica, en forma de árbol, cuyos nodos internos están marcados con operadores lógicos generalizados (fuzzy) y cuyos nodos hoja se asocian con predicados difusos sobre los atributos de entrada. Un clasificador de árboles de patrones se compone de un conjunto de tales árboles patrón: uno para cada etiqueta de clase. En términos de precisión de la clasificación, el método ha mostrado un rendimiento prometedor en estudios experimentales
Modelado Difuso granular con Hipercajas Evolutivas en Espacio Multidimensional de Señales de EEG (Granular Fuzzy Modelling with Evolving Hyperboxes in Multi-Dimensional Space of EEG Signals)
Un enfoque para la construcción de un modelo que está diseñado fundamentalmente alrededor de gránulos de información donde dichos gránulos de información se representan como hipercajas. Varios estudios se han centrado en la construcción de un conjunto de hipercajas alrededor de los datos; uno de ellos es un algoritmo de red neuronal (NN) Min-Max.
Modelos Difusos Granulares
Este tema está relacionado con el diseño de modelos difusos granulares. Se explota un concepto de granularidad de información mediante el desarrollo de un modelo representada como una red de una colección estructurada intuitivamente de gránulos de intervalos de información descritos en el espacio de salida y una familia de gránulos de información inducidos (en forma de conjuntos difusos) formado en el espacio de entrada.
APLICACIONES DE INTERÉS
Procesamiento de Bio Señales
- Técnicas de procesamiento, análisis y clasificación de llanto de bebe, voz, electroencefalogramas y expresiones faciales aplicadas a la identificación de enfermedades neurológicas en recién nacidos, niños y adultos
- Herramientas avanzadas multimodales no invasivas para la identificación temprana automática de trastornos del espectro autista
- Patrones comúnes espacio-espectrales separables para Interfaces Cerebro Computadora de imagenes de palabras.
- Análisis de componentes ERP (potencial relacionado a eventos) de un solo ensayo utilizando un formador de haz LCMV espacio-temporal
- Single-trial ERP (event related potential) component analysis using a spatio-temporal LCMV beam former
- Un sistema de nariz electrónica para diagnosticar enfermedades
- Performance of the Levenberg–Marquardt neural network training method in electronic nose applications
Los filtros multivariados pueden ser utilizados para aislar un componente de ERP de interés sin el procedimiento de promediado. Nos gustaría tener la certeza de que la salida del filtro representa con precisión el componente. El método formador de haces espacio-temporal con restricciones lineales varianza mínima (LCM) proporciona una manera precisa e intuitiva para llevar a cabo el análisis de un componente conocido ERP, sin un promedio entre los ensayos o sujetos. La eliminación de promediado permite poner a prueba hipótesis más detalladas y aplicar los modelos estadísticos más poderosos. Por ejemplo, se permite el uso de modelos de regresión multinivel que pueden incorporar entre la variación / estímulo sujeto como efectos aleatorios, probar múltiples efectos simultáneamente y controlar los efectos de confusión mediante regresión parcial.
El diagnóstico médico ha surgido como un área de aplicación prometedora para las narices electrónicas (e-nariz). En este trabajo, se revisa el trabajo llevado a cabo en la Universidad de Warwick en el uso de una nariz electrónica para diagnosticar la enfermedad. En concreto, hemos aplicado una nariz electrónica para la identificación de patógenos de los cultivos y la enfermedad de diagnóstico de muestras de aliento. Estos resultados iniciales sugieren que un e-nariz será capaz de ayudar en el diagnóstico de enfermedades en un futuro próximo.
The focus of this study is to find the appropriateness of the Levenberg–Marquardt (LM) neural network (NN) training algorithm for recognition of odor patterns associated with an electronic nose (e-nose). Multiple time-patterns represent step response of the array of sensors to the odorants. The experiments are performed on four representative classes of odorants: coffees, fragrances, hog farm air, and cola beverages. The odor recognition system is composed of a Karhunen–Loéve (KL) based pre-processing unit, and a feedforward neural network with the LM training algorithm. The parameters of the pre-processing unit and the neural network are fine-tuned using a genetic algorithm. Back-propagation algorithm with adaptive learning rate is selected as a standard neural network training method, for the purpose of comparison. The results of the experiments indicate that the LM algorithm provides high correct recognition ratios. In addition, the results confirm that the LM method outperforms the back-propagation (BP) method with adaptive learning rate, for the classes of the odorants provided in this study.
Resultados del método de formación de redes neuronales de Levenberg-Marquardt en aplicaciones nariz electrónica
El objetivo de este estudio es conocer la idoneidad de la formación algoritmo de Levenberg-Marquardt (LM) de red neural (NN) para el reconocimiento de patrones de olores asociados con una nariz electrónica (e-nariz). tiempos de patrones múltiples representan respuesta de paso de la matriz de sensores para los odorantes. Los experimentos se realizaron en cuatro clases representativas de los odorantes: cafés, fragancias, aire granja de cerdos, y las bebidas de cola. El sistema de reconocimiento de olor se compone de un Karhunen-Loeve (KL) unidad de pre-procesamiento basado en, y una red neuronal feedforward con el algoritmo de entrenamiento LM. Los parámetros de la unidad de preprocesamiento y la red neural son ajustado utilizando un algoritmo genético. algoritmo de retropropagación con la tasa de aprendizaje adaptativo es seleccionado como un método de entrenamiento de la red neural estándar, con el propósito de comparación. Los resultados de los experimentos indican que el algoritmo de LM proporciona altas relaciones de reconocimiento correcto. Además, los resultados confirman que el método de LM supera el método de retropropagación (BP) con la tasa de aprendizaje adaptativo, para las clases de los odorantes proporcionados en este estudio.
- Las narices electrónicas: Las solicitudes de las industrias alimentarias y farmacéuticas