En general, las acciones del agente determinan, no sólo la recompensa inmediata, sino también (por lo menos en forma probabilística) el siguiente estado del ambiente.
Los problemas con refuerzo diferido se pueden modelar como procesos de decisión de Markov (MDPs).
El modelo es Markoviano si las transiciones de estado no dependen de estados anteriores.
En aprendizaje por refuerzo se asume que se cumple con la propiedad
Markoviana y las probabilidades de transición están dadas por:
Lo que se busca es estimar las funciones de valor. Esto es, qué tan bueno es estar en un estado (o realizar una acción).
La noción de ``qué tan bueno'' se define en términos de recompensas futuras o recompensas esperadas.
La política ![]() es un mapeo de cada estado
es un mapeo de cada estado ![]() y acción
y acción
![]() a la probabilidad
a la probabilidad ![]() de tomar la
acción
de tomar la
acción ![]() estando en estado
estando en estado ![]() . El valor de un estado
. El valor de un estado ![]() bajo
la política
bajo
la política ![]() , denotado como
, denotado como ![]() , es el refuerzo
esperado estando en estado
, es el refuerzo
esperado estando en estado ![]() y siguiendo la política
y siguiendo la política ![]() .
.
Este valor esperado se puede expresar como:
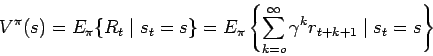
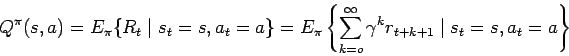
Las funciones de valor óptimas se definen como:
Las cuales se pueden expresar como las ecuaciones de optimalidad de Bellman: