Uno de los enfoques más usados dentro de aprendizaje es el aprendizaje supervisado a partir de ejemplos (pares entradas - salida provistos por el medio ambiente), para después predecir la salida de nuevas entradas.
Cualquier sistema de predicción puede verse dentro de este paradigma, sin embargo, ignora la estructura secuencial del mismo.
En algunos ambientes, muchas veces se puede obtener sólo cierta retroalimentación o recompensa o refuerzo (e.g., gana, pierde).
El refuerzo puede darse en un estado terminal y/o en estados intermedios.
Los refuerzos pueden ser componentes o sugerencias de la utilidad actual a maximizar (e.g., buena movida).
En aprendizaje por refuerzo (RL) el objetivo es aprender cómo mapear situaciones a acciones para maximizar una cierta señal de recompensa.
Promesa: programar agentes mediante premio y castigo sin necesidad de especificar cómo realizar la tarea.
Diferencias con otro tipo de aprendizaje:
En RL un agente trata de aprender un comportamiento mediante interacciones de prueba y error en un ambiente dinámico e incierto.
En general, al sistema no se le dice qué acción debe tomar, sino que él debe de descubrir qué acciones dan el máximo beneficio.
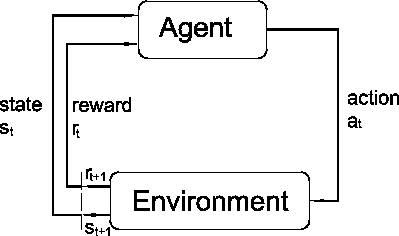
En un RL estandar, un agente está conectado a un ambiente por medio
de percepción y acción (ver figura 11.1). En cada
interacción el agente recibe como
entrada una indicación de su estado actual (![]() ) y selecciona
una acción (
) y selecciona
una acción (![]() ). La acción cambia el estado y el agente
recibe una señal de refuerzo o recompensa (
). La acción cambia el estado y el agente
recibe una señal de refuerzo o recompensa (
![]() ).
).
El comportamiento del agente debe de ser tal que escoga acciones que tiendan a incrementar a largo plazo la suma de las recompensas totales.
El objetivo del agente es encontrar una política (![]() ), que mapea
estados a acciones que maximice a largo plazo el refuerzo.
), que mapea
estados a acciones que maximice a largo plazo el refuerzo.
En general el ambiente es no-determinístico (tomar la misma acción en el mismo estado puede dar resultados diferentes).
Sin embargo, se asume que el ambiente es estacionario (esto es, las probabilidades de cambio de estado no cambian o cambian muy lentamente).
Aspectos importantes: (i) se sigue un proceso de prueba y error, y (ii) la recompensa puede estar diferida.
Otro aspecto importante es el balance entre exploración y explotación. Para obtener buena ganancia uno prefiere seguir ciertas acciones, pero para saber cuáles, se tiene que hacer cierta exploración. Muchas veces depende de cuánto tiempo se espera que el agente interactue con el medio ambiente.
La caracterización de esta problemática está dada por procesos de decisión de Markov o MDP.
Un MDP modela un problema de decisión sequencial en donde el sistema evoluciona en el tiempo y es controlado por un agente.
La dinámica del sistema esta determinada por una función de transición de probabilidad que mapea estados y acciones a otros estados.
Formalmente, un MDP es una tupla
![]() . Los elementos
de un MDP son:
. Los elementos
de un MDP son:
![]() es una función de transición
de estados dada como una distribución de probabilidad. La
probabilidad de alcanzar el estado
es una función de transición
de estados dada como una distribución de probabilidad. La
probabilidad de alcanzar el estado ![]() al realizar la acción
al realizar la acción
![]() en el estado
en el estado ![]() , que se puede denotar como
, que se puede denotar como
![]() .
.
Las recompensas están dadas por el ambiente, pero los valores se deben de estimar (aprender) en base a las observaciones.
Aprendizaje por refuerzo aprende las funciones de valor mientras interactua con el ambiente.