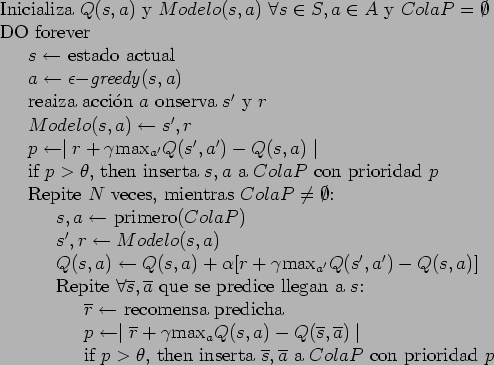Asumamos que tenemos un modelo del ambiente, esto es, que podemos predecir el siguiente estado y la recomepensa dado un estado y una acción.
La predicción puede ser un conjunto de posibles estados con su probabilidad asociada o pouede ser un estado que es muestreado de acuerdo a la distribución de probabilidad de los estados resultantes.
Dado un modelo, es posible hacer planificación. Lo interesante es que podemos utilizar los estados y acciones utilizados en la planificación también para aprender. De hecho al sistema de aprendizaje no le importa si los pares estado-acción son dados de experiencias reales o simuladas.
Dado un modelo del ambiente, uno podría seleccionar
aleatoriamente un par estad-acción, usar el modelo para predecir
el siguiente estado, obtener una recompensa y actualizar valores
![]() . Esto se puede repetir indefinidamente hasta converger a
. Esto se puede repetir indefinidamente hasta converger a ![]() .
.
El algoritmo Dyna-Q combina experiencias con planificación para aprender más rápidamente una política óptima.
La idea es aprender de experiencia, pero también usar un modelo para simular experiencia adicional y así aprender más rápidamente (ver tabla 11.10).
El algoritmo de Dyna-Q selecciona pares estado-acción aleatoriamente de pares anteriores. Sin embargo, la planificación se puede usar mucho mejor si se enfoca a pares estado-acción específicos.
Por ejemplo, enfocarnos en las metas e irnos hacia atrás o más generalmente, irnos hacia atrás de cualquer estado que cambie su valor.
Los cambios en las estimaciones de valor ![]() o
o ![]() pueden cambiar,
cuando se está aprendiendo o si el ambiente cambia y un valor
estimado deja de ser cierto.
pueden cambiar,
cuando se está aprendiendo o si el ambiente cambia y un valor
estimado deja de ser cierto.
Lo que se puede hacer es enfocar la simulación al estado que cambio su valor. Esto nos lleva a todos los estados que llegan a ese estado y que también cambiarían su valor.
Esto proceso se puede repetir sucesivamente, sin embargo, algunos estados cambian mucho más que otros. Lo que podemos hacer es ordenarlos y cambiar solo los que rebacen un cierto umbral. Esto es precisamente lo que hacer el algoritmo de prioritized sweeping (ver tabla 11.11).
![\begin{table}
\begin{tabbing}
123\=123\= \kill
Inicializa $Q(s,a)$\ y $Modelo(s,...
...\alpha [r + \gamma \mbox{max}_{a'}
Q(s',a') - Q(s,a)]$
\end{tabbing}\end{table}](img575.png)