Están entre métodos de Monte Carlo y TD de un paso.
Los métodos Monte Carlo realizan la actualización considerando la secuencia completa de recompensas observadas.
La actualización de los métodos de TD la hacen utilizando únicamente la siguiente recompensa.
La idea de las trazas de elegibilidad es considerar las recompensas de
![]() estados posteriores (o afectar a
estados posteriores (o afectar a ![]() anteriores).
anteriores).
Si recordamos:
Lo que se hace en TD es usar:
Sin embargo, hace igual sentido hacer:
En la práctica, más que esperar ![]() pasos para actualizar
(forward view), se realiza al revés (backward
view). Se guarda información sobre los estados por los que se
pasó y se actualizan hacia atrás las recompensas (descontadas
por la distancia). Se puede probar que ambos enfoques son equivalentes.
pasos para actualizar
(forward view), se realiza al revés (backward
view). Se guarda información sobre los estados por los que se
pasó y se actualizan hacia atrás las recompensas (descontadas
por la distancia). Se puede probar que ambos enfoques son equivalentes.
Para implementar la idea anterior, se asocia a cada estado o par
estado-acción una variable extra, representando su traza de
elegibilidad (eligibility trace) que denotaremos por ![]() o
o
![]() .
.
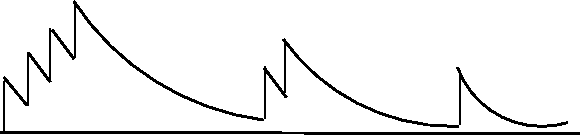
Este valor va decayendo con la longitud de la traza creada en cada episodio. La figura 11.3 muestra este comportamiento.
Para ![]() :
:
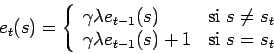
Para SARSA se tiene lo siguiente:
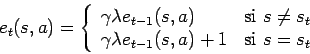
El algoritmo para
![]() viene descrito en la
tabla 11.9.
viene descrito en la
tabla 11.9.
Para Q-learning como la selección de acciones se hace, por ejemplo,
siguiendo una política ![]() greedy, se tiene que tener
cuidado, ya que a veces los movimientos, son movimientos
exploratorios.
greedy, se tiene que tener
cuidado, ya que a veces los movimientos, son movimientos
exploratorios.
Aquí se puede mantener historia de la traza solo hasta el primer movimiento exploratorio, ignorar las acciones exploratorias, o hacer un esquema un poco más complicado que considera todas las posibles acciones en cada estado.