Búsqueda ``greedy'' minimiza ![]() reduciendo la búsqueda,
pero no es ni óptima ni completa. Búsqueda de costo uniforme
minimiza el costo acumulado
reduciendo la búsqueda,
pero no es ni óptima ni completa. Búsqueda de costo uniforme
minimiza el costo acumulado ![]() y es completa y óptima, pero
puede ser muy ineficiente.
y es completa y óptima, pero
puede ser muy ineficiente.
Se pueden combinar las dos sumandolas, usando para cada nodo la
siguiente heurística:
![]() .
.
La estrategia se puede probar que es completa y óptima si ![]() nunca sobre-estima el costo. Tal función se le conoce como una
heurística admisible.
nunca sobre-estima el costo. Tal función se le conoce como una
heurística admisible.
Breadth-first se puede ver como un caso especial de A![]() si
si ![]() y
y ![]() para todos sus sucesores (el costo de ir de un nodo
padre a un nodo hijo).
para todos sus sucesores (el costo de ir de un nodo
padre a un nodo hijo).
Si ![]() es admisible,
es admisible, ![]() nunca hace sobrestimaciones. Una función
es admisible si
nunca hace sobrestimaciones. Una función
es admisible si
![]() .
.
Propiedades de A![]() :
:
Una heurística ![]() se dice consistente si:
se dice consistente si:
Cualquier heurística consistente es también admisible.
Una heurística ![]() se dice monotona si:
se dice monotona si:
Se puede probar que una heurística es monotónica si obedece la desigualdad del triangulo, osea que la suma de sus lados no pueden ser menores a el otro lado.
De hecho, las dos propiedades son equivalentes.
Si tenemos heurísticas no monotónicas, podemos usar el costo del
padre para garantizar que el costo nunca decrece:
![]() . Esto se llama
. Esto se llama ![]() .
.
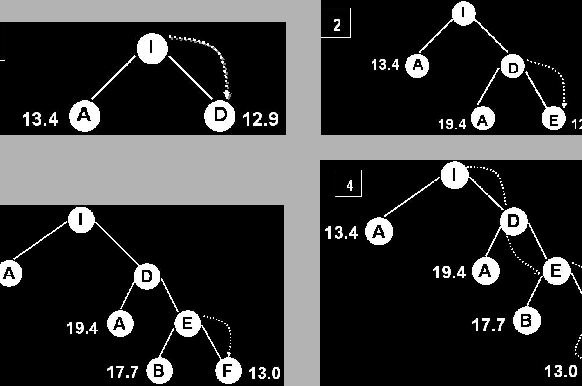
Si ![]() nunca decrece al recorrer los caminos, se pueden ``dibujar''
contornos (``curvas de nivel'').
nunca decrece al recorrer los caminos, se pueden ``dibujar''
contornos (``curvas de nivel'').
Si ![]() (costo uniforme) las bandas con ``circulares'' alrededor
del estado inicial.
(costo uniforme) las bandas con ``circulares'' alrededor
del estado inicial.
Con heurísticas más precisas, las bandas tienen a alargarse hacia las metas.
A![]() va expandiendo todos los nodos en estos contornos hasta llegar
al contorno de la meta, en donde posiblemente expanda algunos antes de
llegar a la solución.
va expandiendo todos los nodos en estos contornos hasta llegar
al contorno de la meta, en donde posiblemente expanda algunos antes de
llegar a la solución.
Básicamente si no se expanden todos los nodos de un contorno se puede perder la solución óptima.
A![]() es completo, óptimo y eficientemente óptimo (ningún otro
algoritmo óptimo garantiza expander menor nodos que A
es completo, óptimo y eficientemente óptimo (ningún otro
algoritmo óptimo garantiza expander menor nodos que A![]() ).
).
Sin embargo, el número de nodos normalmente crece exponencialmente con la longitud de la solución, a menos que el error en la solución no cresca más rápido que el logaritmo del costo actual del camino.
Generalmente A![]() se queda sin espacio (antes de consumir el tiempo).
se queda sin espacio (antes de consumir el tiempo).
Si se conoce un estimado del costo óptimo, se pueden podar ciertos nodos. Por ejemplo, si un depth-first encuentra una meta, ésta nos puede servir para eliminar nodos con costos mayores.
Usualmente el factor de arborecencia efectivo de una heurística se mantiene más o menos constante sobre una gran variadad de instancias del problema, por lo que medidas experimentales en pequeñas conjuntos pueden dar una guía adecuada de lo útil de la heurística.
Idealmente la heurísitca se debe de acercar a 1.
Una heurística (![]() ) se dice que domina a otra (
) se dice que domina a otra (![]() ) si
) si ![]() expande en promedio menos nodos que
expande en promedio menos nodos que ![]() .
.
A![]() expande todos los nodos con
expande todos los nodos con ![]()
![]() expande todos
los nodos que cumplan
expande todos
los nodos que cumplan
![]() . Como
. Como ![]() es por lo menos
tan grande que
es por lo menos
tan grande que ![]() para todos los nodos, todo nodo expandido por
para todos los nodos, todo nodo expandido por
![]() también es expandido por
también es expandido por ![]() (quien posiblemente expande
otros).
(quien posiblemente expande
otros).
Por lo que siempre es mejor usar la heurística que de valores más grandes, siempre y cuando no sobre-estime.
| Costo de búsqueda | Arborecencia | |||||
| efetiva | ||||||
| d | IDS | A |
A |
IDS | A |
A |
| 2 | 10 | 6 | 6 | 2.45 | 1.79 | 1.79 |
| 4 | 112 | 13 | 12 | 2.87 | 1.48 | 1.45 |
| 6 | 680 | 20 | 18 | 2.73 | 1.34 | 1.30 |
| 8 | 6384 | 39 | 25 | 2.80 | 1.33 | 1.24 |
| 10 | 47127 | 93 | 39 | 2.79 | 1.38 | 1.22 |
| 12 | 364404 | 227 | 73 | 2.78 | 1.42 | 1.24 |
| 14 | 3473941 | 539 | 113 | 2.83 | 1.44 | 1.23 |
| 16 | 1301 | 211 | 1.45 | 1.25 | ||
| 18 | 3056 | 363 | 1.46 | 1.26 | ||
| 20 | 7276 | 676 | 1.47 | 1.27 | ||
| 22 | 18094 | 1219 | 1.48 | 1.28 | ||
| 24 | 39135 | 1641 | 1.48 | 1.26 | ||