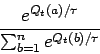Los métodos de Monte Carlo, solo requieren de experiencia y la actualización se hace por episodio más que por cada paso.
El valor de un estado es la recompensa esperada que se puede obtener a partir de ese estado.
Para estimar ![]() y
y ![]() podemos tomar estadísticas
haciendo un promedio de las recompensas obtenidas. El algoritmo para
podemos tomar estadísticas
haciendo un promedio de las recompensas obtenidas. El algoritmo para
![]() está descrito en la tabla 11.4.
está descrito en la tabla 11.4.
Para estimar pares estado-acción (![]() ) corremos el peligro de
no ver todos los pares, por lo que se busca mantener la exploración.
Lo que normalmente se hace es considerar solo políticas estocásticas
que tienen una probabilidad diferente de cero se seleccionar todas las
acciones.
) corremos el peligro de
no ver todos los pares, por lo que se busca mantener la exploración.
Lo que normalmente se hace es considerar solo políticas estocásticas
que tienen una probabilidad diferente de cero se seleccionar todas las
acciones.
Con Monte Carlo podemos alternar entre evaluación y mejoras en base a cada episodio. La idea es que después de cada episodio las recompensas observadas se usan para evluar la política y la política se mejora para todos los estados visitados en el episodio. El algoritmo viene descrito en la tabla 11.5.
Existen dos formas para asegurar que todas las acciones pueden ser seleccionadas indefinidamente:
Esto es lo que hace Q-learning, lo cual simplifica el algoritmo.
Ejemplos de políticas de selección de acciones son: